图像捕捉
“图像捕捉”,也就是创建数字图像的过程,从根本上影响着用户能够在屏幕上看到什么。以非常高的分辨率捕捉的图像,在每一英寸的空间内记录了大量的细节,看起来会更加逼真,放大到很高的倍率都不会出现模糊。然而,高分辨率的代价是文件巨大,导致加载速度很慢。因此,在图像的质量和使用便利性之间必须达到一个平衡。
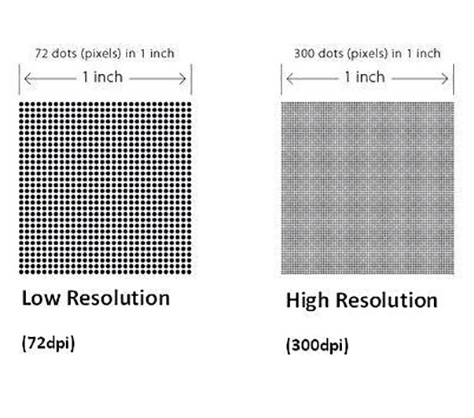
我们从微缩胶片捕捉的图像分辨率是400dpi(每英寸点数),与美国国会图书馆数字化项目的标准相一致。而对于中世纪手稿,则最好有更高的分辨率(可能需要高达1200dpi),以便能够看到复杂的细节,而报纸400dpi的分辨率则是可读性和文件大小易管理性之间的合理平衡。
另一件需要决定的事情是,图像是否要捕捉为双色调(也就是简单的黑与白)或灰度(允许有细微的色调和不同的明暗度)。两种都各有优缺点。双色调图像可以让文字在白色背景下非常突出、清晰可见,通常用于历史报纸。然而,它令插图和照片质量不佳。相反,灰度图像能更好的处理照片和插图,但也会拾取纸张的背景纹理,这就意味着图像有着灰色的“噪音”背景。随着二十世纪文献中的插图越来越多,我们需要使用灰度来处理更晚期的内容。因此,我们采用了混合的方式,1962年以前的图像用双色调,而这之后随着彩色和真半色调照片更多地出现,则改为灰度。用户将会注意到这一时间点前后图像的差别。
例如,《每日邮报》在1971年从大报改为了小报版面。用户会注意到大报时期的数字化文件大小明显高于小报时期的数字化文件,特别是灰度图像。为了让文件大小易于管理,小报时期之前的《每日邮报》图像幅面被减小了50%,因此该档案库中大报时期的各期报纸图像实际大小与小报时期的相同。从多个角度来说,这让用户在屏幕上阅读报纸更为容易,因为很少有人有大报尺寸的显示器,这是数字版本带来的一种转变。《每日邮报大西洋版》的微缩胶片是400dpi的,图像捕捉为双色调。原版即为小报尺寸,因此数字版的尺寸没有缩减。特刊也是以原有的尺寸捕捉为400dpi全彩色图像。